この記事はVarnish Cache Advent Calendar 2015の1日目の記事になります。
何回か散発的に取り上げたことはあるのですがVSL-Queryの使い方についてまとまっては書いていなかったので書いてみます。
varnishlogのフォーマットの説明についてはv3の頃の記事ですがVarnishのログにアクセスしてみよう!を参考にしてください。
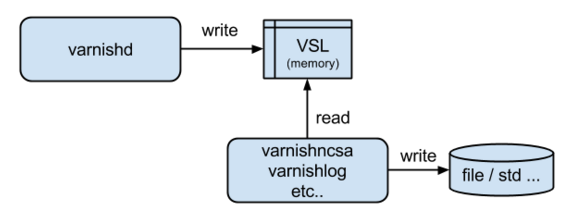
Varnishは他のミドルウェアでよくあるようにアクセスログをファイルに直接書き込むということはせずにリングバッファな共有メモリ(VSM)に出力します。
その際に出力されるログ(VSL)は非常に多岐に渡ります
- ヘッダ(クライアントからのリクエストヘッダやバックエンドからのレスポンスヘッダなど)
- ヘッダへの操作
- どのアクション(vcl_recvなど)が呼ばれて何をリターン(hashなど)したか
- std.logで出力した任意のログ
- などなど
標準ではoffにされていますがonにすることでVCL中のどこのブロックを通過したかもトレースすることも可能です。
varnishncsaやvarnishlogなどの各種ツールはこのログを読んで出力します。
もちろんそのまま使うことも多いのですが、例えばエラーがでた・遅いリクエストだけを抽出したいということがあります。
その際に利用するのがVSL-Queryというもので、要はVSLに対して絞り込みを行う式を作成できます。
varnishncsa -q "respstatus >= 400"
例えばこうすることでステータスコードが400以上のものを絞り込んで出力することができます。
今回はVSL-Query全般についての記事を書こうと思います。
VSL-Query
VSL-Queryは3つの要素からできています。
- ログのグループ化
- トランザクションの階層化
- クエリ評価する
ログのグループ化
グループの種類は4種類あります。
raw
ログ1行を表します(何もグループ化されていない状態)
rawの場合はReqURLなどトランザクションに関わるデータとヘルスチェック等の非トランザクションデータの両方が含まれています。
ログを見た際にvxidが0のものは非トランザクションデータです。
vxid
複数行のログをHTTPトランザクション毎にグループ化します。
例えばクライアントからのトランザクションを処理する際にバックエンドまで問い合わせを行った場合は
クライアント<->VarnishとVarnish<->バックエンドの2トランザクションに分かれます。
なお、このデータにはraw時に含まれていたトランザクションにかかわらないデータ(ヘルスチェックなど)は含まれていません。
ちなみにvxidとはVarnish Transaction IDの略でトランザクションを識別するためのIDです。
X-Varnishヘッダで挿入される数値についてもそれです。
request
複数のHTTPトランザクションをまとめてリクエスト毎にします。
ESIやrestartを利用した場合はrequest内にrequestが含まれる事があります。
基本的にこの粒度で見ていればクライアント・Varnish・バックエンドでの流れがわかるので便利です。
session
複数のリクエストをまとめてセッション毎にします。
複数のリクエストが含まれるケースはkeep-aliveが有効な場合です。
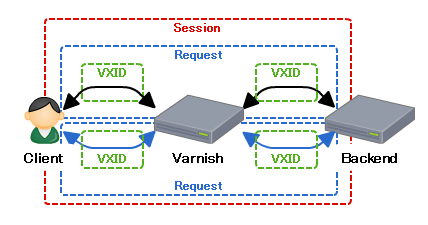
図にするとこんな感じです。
トランザクションの階層化
vsl-queryではログのグループ化を行うと同時に階層構造を作成します。
例えばVarnishからバックエンドへのトランザクションはその前にクライアントからVarnishへのトランザクションがあります。当然ですがそれは親子関係です。
トランザクション間の親子関係を作っているので、当然ながらログ一行ずつをグループとしているrawやトランザクション単体をグループとしているvxidでは階層化は行われません。
requestとsessionにおいて階層化が行われます。
実際に例で考えてみましょう。
グループ分けをrequestでVarnishがクライアントのリクエストを受付して、バックエンドに問い合わせして返却するケースでの階層は以下になります。
[Lv1] +ClientとVarnishのやりとり [Lv2] | +VarnishとBackendのやり取り
次にグループ分けをsessionにしてそのセッションからのリクエストが2つあった場合は以下になります。
[Lv1] +セッション [Lv2] | +ClientとVarnishのやりとり [Lv3] | | +VarnishとBackendのやり取り [Lv2] | +ClientとVarnishのやりとり [Lv3] | | +VarnishとBackendのやり取り
実際のログだとどのように出力されるかというと(グループ分け=request)
* << Request >> 44645623 - Begin req 44645581 rxreq - Timestamp Start: 1448894183.500204 0.000000 0.000000 - Timestamp Req: 1448894183.500204 0.000000 0.000000 - ReqStart ****** 47457 - ReqMethod GET ... - VCL_return fetch - Link bereq 44645624 pass - Timestamp Fetch: 1448894183.708612 0.208408 0.208408 - RespProtocol HTTP/1.1 ... - Timestamp Resp: 1448894183.710162 0.209958 0.001442 - ReqAcct 881 0 881 1994 7476 9470 - End ** << BeReq >> 44645624 -- Begin bereq 44645623 pass -- Timestamp Start: 1448894183.500314 0.000000 0.000000 -- BereqMethod GET -
こうなります。
なおレベルは1スタートとなります。
クエリ評価
グループとクエリの関係
何に対してクエリ評価を行うかというと、先ほどグループ化した中でqueryを評価して、一致するものがあればそのグループを出力します。
つまりグループがrawの場合は1行単位で評価するので
# varnishlog -graw -q "respstatus >= 400" 61146578 RespStatus c 404 35190583 RespStatus c 404 52614757 RespStatus c 404 52656165 RespStatus c 400
条件にひっかかる行だけが出力されます。
逆にsessionで評価した場合
# varnishlog -gsession -q "respstatus >= 400" * << Session >> 60621569 - Begin sess 0 HTTP/1 - SessOpen ******* 62077 :80 ******* 80 1448897491.204370 99 - Link req 60621570 rxreq - Link req 60621571 rxreq - VSL store overflow - End synth ** << Request >> 60621570 -- Begin req 60621569 rxreq ... -- RespStatus 200 -- RespReason OK ... -- End ** << Request >> 60621571 ... -- RespStatus 404 -- RespReason Not Found ...
同一セッション内で404を返しているリクエストがあるためステータス200で返してるリクエストも引っかかってきています。
たとえば400以上のステータスコードを吐いてるリクエストのみを取得するのであればグループはrequest若しくはvxidが適切でしょう。
このようにグループ分けは狙ったログを出力する際には非常に重要です。
クエリの文法
クエリは次のように書きます。
[レコード] [演算子] [被演算子]
例: respstatus >= 400
レコードは次のように書きます。
{階層レベル}タグリスト:レコードのPrefix[フィールド]
これは全て指定する必要はなく、最低限タグだけを指定すればOKです。
フルで指定するとこのような指定になります
{2+}Timestamp:Resp[2]
1つずつ説明します。
階層レベル ( {2+}Timestamp:Resp[2] )
先ほど説明したトランザクションの階層化におけるレベルになります。
レベルは次のような指定の仕方があります。
| 指定方法/サンプル | 説明 |
|---|---|
| {2} | Lv == 2 |
| {2+} | Lv >= 2 |
| {2-} | Lv <= 2 |
ちなみに{0+}も指定できます。この場合は全てのレベルと一致します
タグリスト ( {2+}Timestamp:Resp[2] )
タグの一覧はこちらになります
また、複数のタグを以下のように指定できます
| 指定方法 | サンプル | 説明 |
|---|---|---|
| [tag],[tag] | respheader,reqheader | カンマ区切りでタグをを完全一致で指定します。 |
| *[tag名の一部] | *header | 後方一致するタグを指定します。 |
| [tag名の一部]* | resp* | 前方一致するタグを指定します。 |
[,]と[*]は同時に指定可能です。
また、[*]を途中で挿入することもできません。
#OKパタン req*,resp* #NGパタン *eq*
レコードのPrefix ( {2+}Timestamp:Resp[2] )
データが「:」で区切られている場合はそれをキーとして使えます。
例えばTimestampでのイベントラベルやReqHeaderなどのヘッダ名に対して使用できます。
例:ReqHeader:User-Agent #リクエストヘッダのUser-Agentを指定
フィールド ( {2+}Timestamp:Resp[2] )
データがスペースで区切られている場合はそれを区切り文字として1スタートで指定できます。
例えばレスポンスが完了するまでにかかった時間を指定したい場合は以下のようにします。
例:Timestamp:Resp[2] #Timestamp:Respの第2フィールドを指定
演算子
演算子は以下のものが使用できます
| タイプ | 演算子 |
|---|---|
| 数値(int,float) | == != < <= > >= |
| 文字列 | eq ne |
| 正規表現 | ~ !~ |
被演算子
以下が使用できます
| タイプ | サンプル |
|---|---|
| int | 100 |
| float | 0. 0.8 |
| string | hoge |
| regex | (iPad|iPhone) |
なおregexはpcre(3)を利用しているので、例えば大小文字を無視する場合は以下のようにします
(?i)wget
文字列や正規表現は基本的に[‘]か[“]でquoteするのが良いかと思いますが、以下の文字のみで構成する場合はquoteは不要です
a-z A-Z 0-9 + - _ . *
論理演算子
先ほどの[レコード] [演算子] [被演算子]を一つの式として、論理演算子と組み合わせることで複数の条件を指定できます。
使用可能なのは以下です。
| 指定方法 | 説明 |
|---|---|
| not [expr] | exprが一致しない場合に真 |
| [expr1] and [expr2] | expr1と2が両方とも真の場合に真 |
| [expr1] or [expr2] | expr1か2のどちらかが真の場合に真 |
もちろん[expr1] and not [expr2]や[expr1] or not [expr2]の指定も可能です。
その他
他には以下の様な指定が可能です。
| 指定方法/サンプル | 説明 |
|---|---|
| respstatus | タグ名だけを指定するとそのタグが存在する場合に真となる |
| (fetcherror ~’no backend’ and respstatus == 503) or respstatus == 400 | ()を式中に含めることが可能です |
実際のサンプル
自分がよく使うqueryの一部を紹介します
vcl_log:[key] ~ 任意の文字列
std.log(“key:文字列”)でデバッグ用の文字列を仕込んで、それでマッチさせます。
場合によっては数値を利用して比較演算子と組み合わせるのも便利です。
reqheader:Host ~ [ホスト名]
ホスト名を絞って表示したい場合
respstatus >=400
エラーを起こしたもの
最後に
これ書いてる時にバグっぽいのを見つけたので調べてバグならチケット切ってきます(その部分の記述は削りましたw)
