ここ最近いくつかのサイトを見ていて、アレ?妙に重くない?とDevTools等を見てみたらいろいろな問題点を見つけました。
例えばベースページが重いというのもあるのですが、単純にリソースが大きすぎる、ヘッダがおかしい等少しの工夫で閲覧をする人たちは快適になるだろうというのを思いました。
正直なところ今回記述する内容はいろんなサイトや書籍では触れられてはいるのですが、サイトを見回って共通で考慮が漏れていて、余りサイトに変更を加えずに効果がでそうなのを纏めてみました。
そのページを見るのにどれだけのダウンロードが必要ですか?
最近はPC環境もモバイル環境もより強力になり、リッチなコンテンツをストレスなく見ることが可能になりました。
マシンスペックやブラウザの高速化等いろいろありますが、ラストワンマイルのNW帯域が改善したのが大きいと個人的には感じています。
しかし、それに甘えて不必要なリソースをダウンロードさせてないでしょうか?
最近のChromeはLTEや3GなどのNW環境をエミュレーションしてどのように表示され、どの程度時間がかかるかなどがわかるので早速チェックしていきましょう。(もちろん実機が一番なので簡易的手段です)
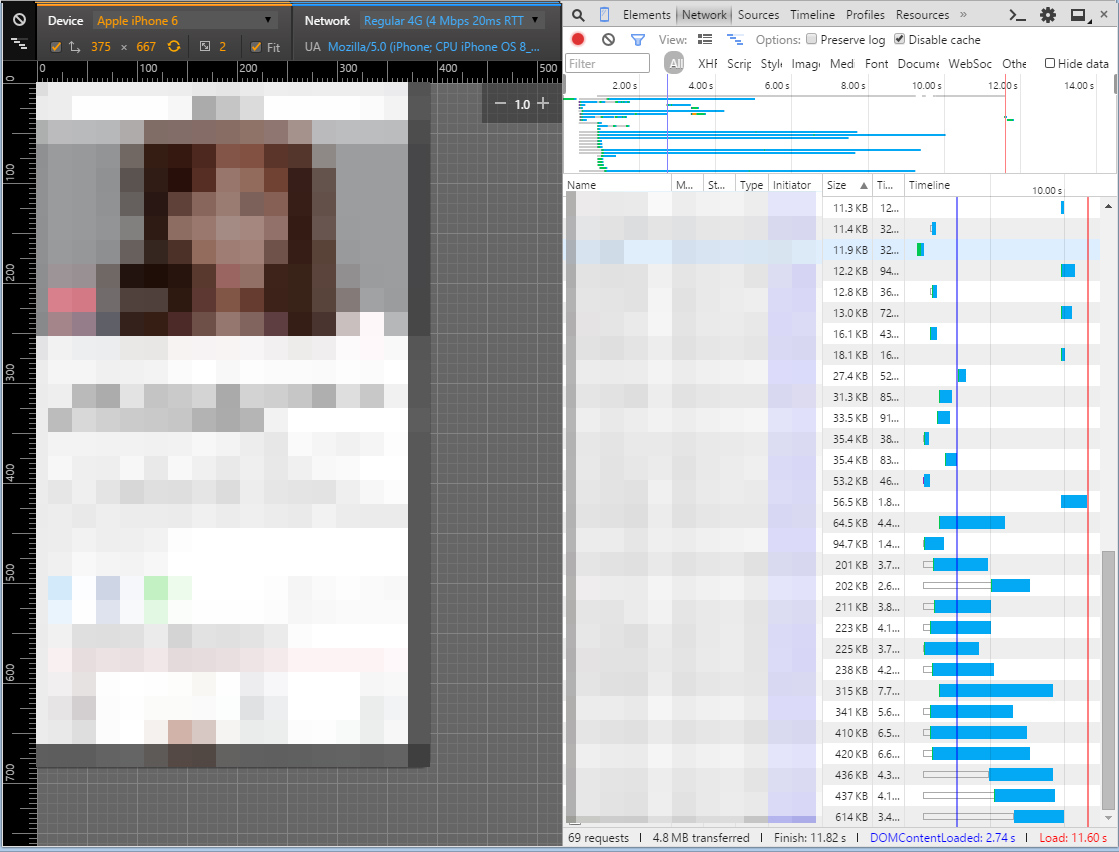
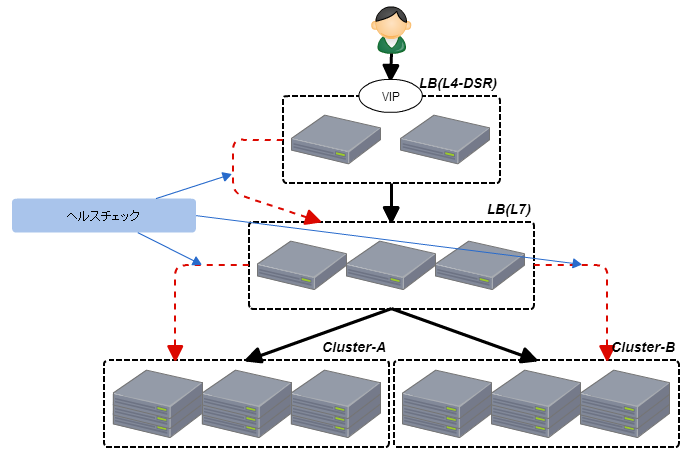
iPhone6(LTE)偽装 11.82sec 4.8MB
例えばこのサイトはスマホページで4.8MBもダウンロードしています。
通信環境の悪いところで快適に閲覧できるようなサイトでしょうか?
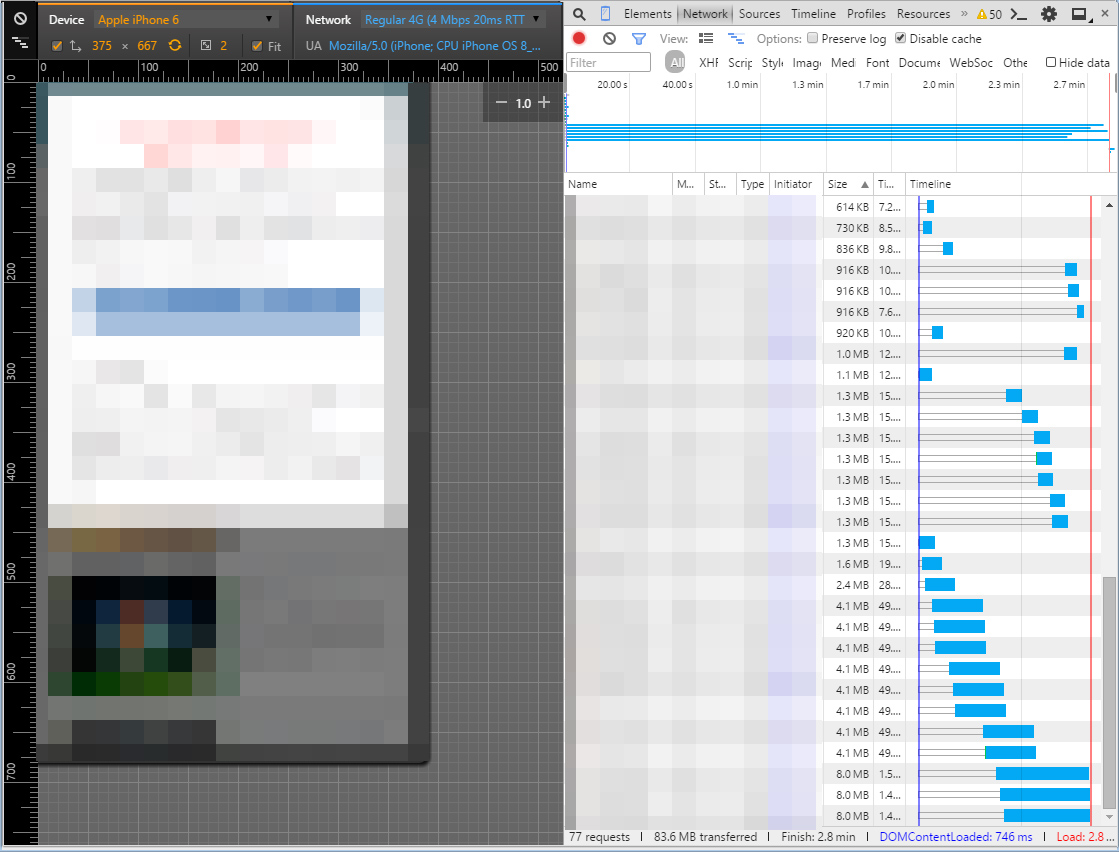
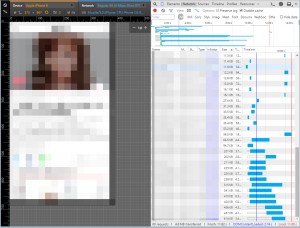
iPhone6(LTE)偽装 2.8min 83.6MB
このページに関しては13回見るとキャリアの制限に達するというそもそも論外なレベルです。
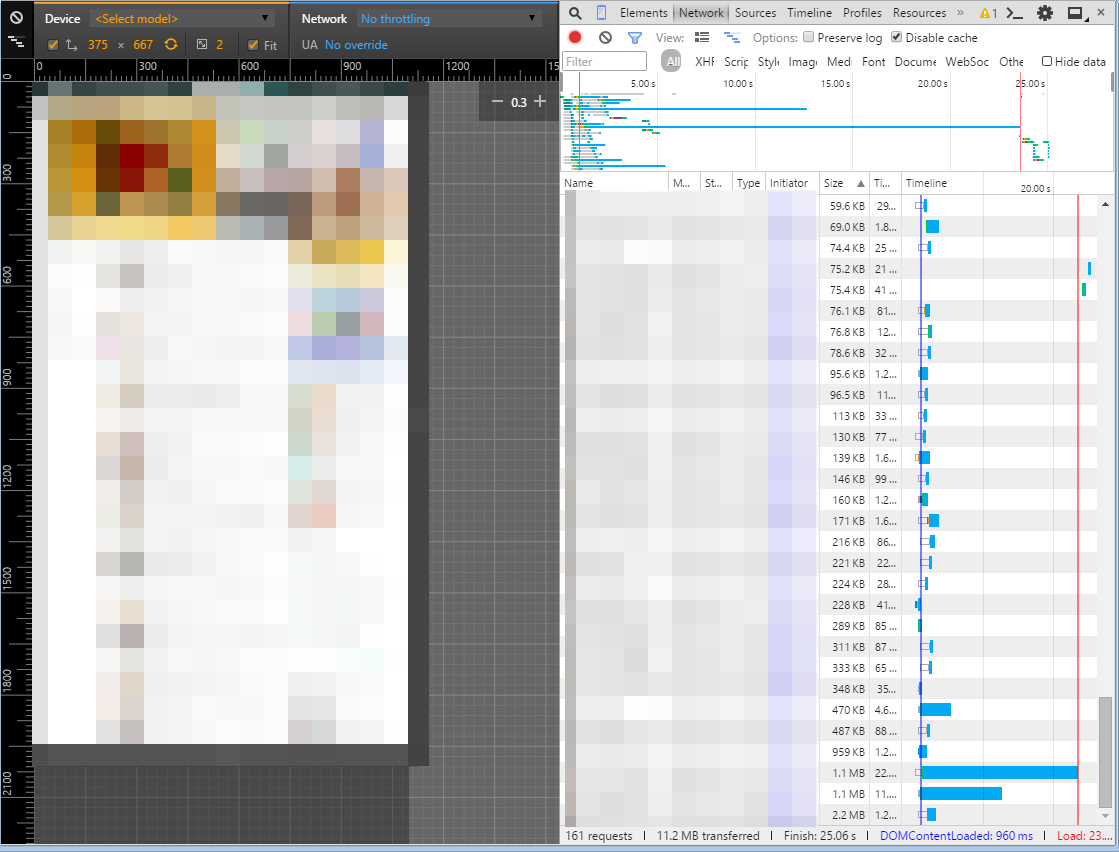
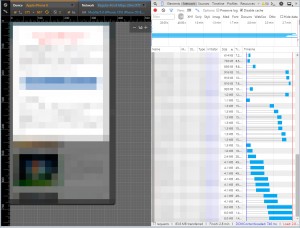
PC(FTTH) 25.06sec 11.2MB
これはとあるキュレーションサイトのトップページなのですが、PC環境ならいいのでしょうか?
例えばお絵かきSNSとして有名なPixivですが
PCのマイページを見たところ4.07sec 3.2MBで、iPhone6(LTE)偽装で3.58sec 1.1MBでした。
画像が主役でダウンロードサイズが大きいだろうと予想されるサイトでもこの程度です。
今回僕が見た問題のあるサイトの多くは不必要に画像のサイズが大きかったり、そもそもクライアントキャッシュが効かなかったりしていました。
失礼ながら開発する際に実機ではあまり見てないように思えます。(見ていたとしてもwifi接続でとか)
重いサイトをでも耐えて見たくなるようなコンテンツがあるような場合や遅くても体感速度は速い場合は違うかもしれませんが、普通に考えて頻繁に見ようとは思わないと思います。
もう使い古されたような話(2006年)ですが、Amazonでは0.1秒遅くなると売上が1%減少するというのもあります。
また、これらの多くのサイトはクラウドで構築されており、多くの場合転送課金が発生しています。
純粋にコスト的観点からでもいいですし、ユーザからの視点でもいいので、まずは自分のサイトを認識するところからはじめましょう。
リソースのリクエスト数を減らそう(INM/IMS)
リソースを見ているとCache-Control/Expiresがついていないため
同じリソースを毎回更新されていないかとサーバに問い合わせしているケースが有りました。
そのページでしか利用しない画像ならともかくCSSやjsの用に複数のページで利用されるものもこうだとそれだけでレンダリングが悪化します。
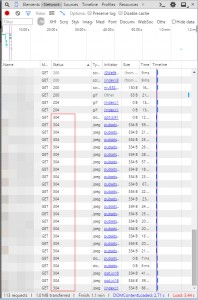
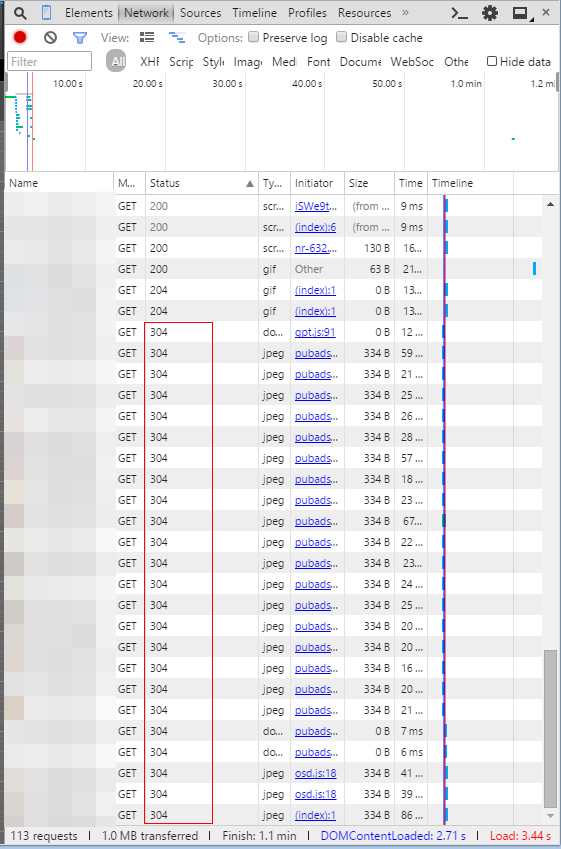
304 Not Modifiedいっぱい
クライアント側がリソースを既に持っている場合はIf-None-Match(INM)もしくはIf-Modified-Since(IMS)リクエストというのを発行して更新があるかをチェックします。
(ちなみにINMはETagをIMSはLast-Modifiedが含む場合に動作し、その両方がなくcache-control/Expiresも無い場合は毎回レスポンスを取得します)
更新がない場合はキャッシュされたリソースを使用しますがそれでもサーバにリクエストする分時間がかかりますし、サーバの負荷やリクエスト課金があるような場合はコスト増にもつながります。
そのためCache-Control/Expires/ETag/Last-Modifiedは適切に指定するべきです。(参考:HTTPキャッシュの作成)
ちなみにCache-Controlだけでも良いのではと思う人もいるかもしれませんが、ETag/Last-Modifiedがあれば期限が切れた際にINM/IMSリクエストが行われリソースに更新が無ければキャッシュをそのまま使うため不必要なダウンロードが発生しなくなります。
TTLの目安
今まで毎回リクエストが飛んでいたところを、じゃあクライアント側でキャッシュを使えるようにしようとあまり考えずに長めにTTLを設定すると問題が起きるかもしれません。
簡単にいうとファイルを更新したのに(当然ですが)クライアント側のキャッシュが変わらないということです。
そのためファイル名にバージョン情報や日付などをつけたりして異なるURLにしてしまうと解決ができます。(ex: hoge.js?20150526)
これは非常に強力ですがテンプレートの修正などが必要になるためすぐに適用できないことも考えられます。
とはいってもTTLを短くしてしまってはあまり意味がありません。
じゃぁどの程度のTTLがあれば良いのでしょうか?
一つの目安ですがサイトの滞在時間を目安とするとよいでしょう。

GoogleAnalyticsより例
見てる間に不要なダウンロードが発生しなければ良いのでそれに合わせてしまえば比較的短く、そして効果的なクライアントキャッシュが出来るでしょう。
もちろんこれは小手先の対応で最終的にはURLを変える対応を行ってTTLは長めに設定するのが良いです。
そのETag適切ですか?
とあるサイトを見ていると304に混じって毎回何故かダウンロードしているものを見つけました。
そこで原因を調べてみるとファイルが更新されていないのにETagが変わるのを発見しました。
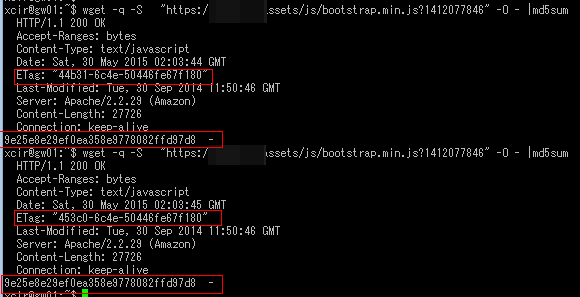
ハッシュ値が同じなのにETagが違うファイル
先ほどのリソースのリクエスト数を減らそうでも触れましたがINMではキャッシュで保持しているETagをサーバにリクエストして更新があればダウンロードを行うものです。
そのためETagが変われば更新されているものとしてダウンロードがされてしまいます。
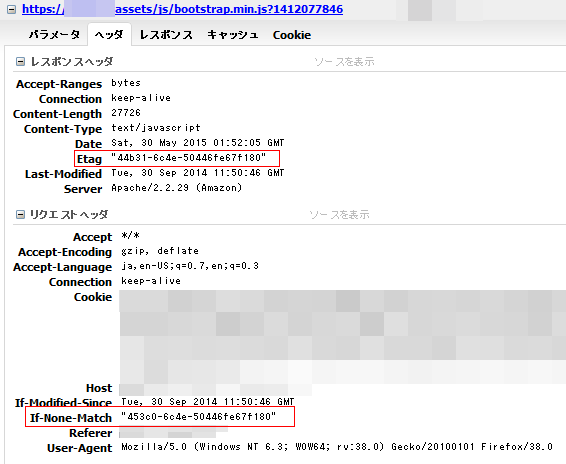
同じファイルなのにETagが違うためボディを取得した例
このサイトの場合はjs/cssで起きていて、なおかつcache-controlがなかったのでページ遷移をする度に運が悪いとこれらのファイルが読み込まれていました(運がよいと304)
ではなぜこういう現象が起きるかというと、大体の場合はサーバ側の設定不備かDeployの問題に分けられると思います。
ApacheのETagのデフォルト値はINode-MTime-Sizeです(参照)
単一サーバで配信する場合はこれで問題は起きないのですが、複数サーバの場合だとサーバ間でINodeが同一でないためここがずれます。
そのためファイルとしては同一であってもETagが変わってしまいます。
これを防ぐにはINodeを使わなければOKです。
次にdeployの問題ですが、単純に複数のサーバに配ってる間に時間がずれてしまうためおきます(MTime部分がズレる)
例えばdeployにrsyncを利用しているのであれば-tオプションを利用してタイムスタンプを維持するようにするとよいでしょう。
コンテンツのgzip圧縮転送を有効にしよう
例えばjquery.js(1.11.2)の場合、gzipの有無でこれだけ違います(確かこの数値はApacheかNginxのデフォルトで取ったので圧縮率上げればもっと行くはず)
| gzip |
Size |
Per |
| Off |
95,952B(94KB) |
100% |
| On |
33,287B(33KB) |
34.7% |
画像などの既に圧縮されているようなものには効かないですがCSSやjs等のテキスト系には非常に効果的です。(もちろんベースページも)
テキスト系のものには適用できるように設定するとよいでしょう
2015/11/02追記
AmazonS3にcssやjsを直接置いているサイトが結構ありますが、gzipの考慮がもれているように思われます。
個人的には画像とかはともかくcss/jsをS3から直接配信するのはオススメしません。(オリジンとして置くには良いと思います)
最近jsで1MBを転送しているサイトを見かけまして少しきになりましたので追記しました。
画像のクオリティを調整しよう
JPGは画像のクオリティ(以下q)を調節することでサイズを大幅に小さくすることが可能です。(PNGも圧縮率等調整することで多少小さくすることは可能)
当然ながらqが低ければ画質は悪化しますがその分小さくなります。
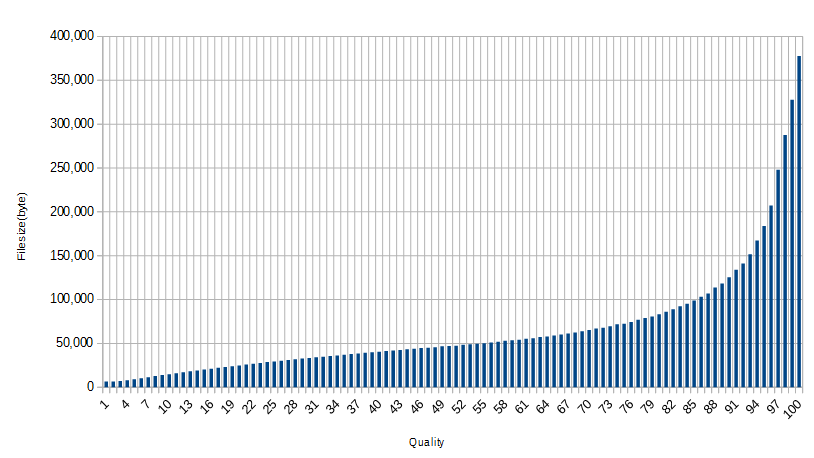
q=100の画像のクオリティを下げていった場合のファイルサイズ
しかしq=90ぐらい落としてもwebで使う分には十分な画質が有ります。

q=100 / 368KB(オリジナル 焼肉奢ってくれる人募集しています)

q=90 / 122KB

q=80 / 81.2KB

q=70 / 63.6KB

q=1 / 6.4KB
どれ位サイズが小さくなるかは画像によって違いますし
どの程度のqが必要かはサイトの特性に対する考慮、その他ベンチマークをする必要はありますが普通は90もあれば十分綺麗です。80でもよく見なければ気づきにくいとおもいます。
また当然のことなのですが元々qが低い画像のqを上げた場合も無意味です。

q=1のものを100にした画像 (30.8KB)
もしサイト画像のqが既に90以下で一括で90にあげようとした場合は逆にサイズが増えるでのできちんと調べておくと良いです。
画像のサイズを適切にしよう / サムネを作ろう
当然ですがサイズが大きい画像はファイルサイズが大きいです。
適切なサイズ・クオリティで作成することでページは軽くなります。
先ほどの画像の元サイズを100%として10%刻みでサイズを落としていくとこうなります(q=100のまま)
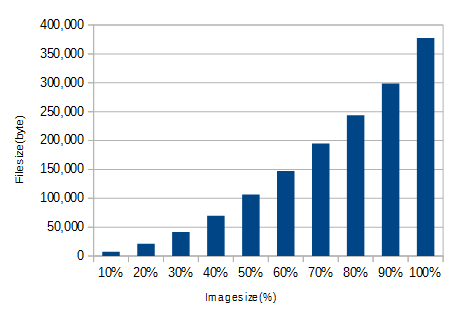
10%刻みで小さくしてみた
なるだけ表示サイズに合わせて画像を生成するべきでしょう。
動的にサイズを指定してサムネイルを作成するMWもあるのでそれとキャッシュを組み合わせるなどしてもよいでしょう。
その写真は本当にPNG(可逆圧縮)が必要ですか?
先ほどの写真(JPG/q=100)をPNG(24bit)に変換するとサイズが大抵の場合膨れます。
| JPG(q=100 667×500) |
PNG(24bit 667×500) |
| 313,885B(306KB) |
597,334B(583KB) |
もちろん8bit(256色以下)であれば小さくはなります。

PNG8(256Color) / 186KB
ですが個人的にはqを下げたほうが良いと思います。
もちろんアイコン等のtooltipはPNG8が良いでしょう。
PageSpeed Insightsを活用しよう
Google先生が割と教えてくれます。
とりあえずかけてみて参考にするとよいでしょう。
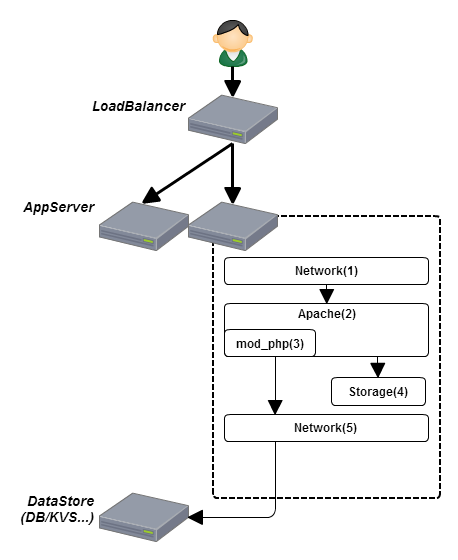
ApacheのMPMの違いとリバースプロキシでのキャッシュ
ApacheでPHPを使う場合大体mod_phpを利用すると思いますがこれはPreforkで動作します。
Preforkは1プロセスが1リクエストを捌くものです。
プロセスはそれぞれで独立したメモリ空間を持つためスレッドで動くworkerに比べ同時に捌けるリクエスト数は少ないです(workerは1スレッド1リクエスト)
これがなんの問題があるかというと画像等の静的リソースをPrefoekで動いているサーバでレスポンスしてしまうことです。
通常、ベースページに紐づく静的リソースは多いため大量のリクエストが来ます、静的なので高速にレスポンス出来ると思いますが無駄にサーバリソースを使っているのは確かです。
そのため可能であれば静的リソースはworkerなサーバでレスポンスして、動的コンテンツのみをpreforkなサーバで返したいところです。
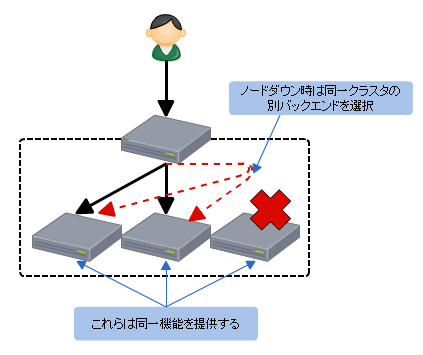
ドメインを分けるのも手ですが、それが難しいばあいはリバースプロキシを入れるのも手です。
リバースプロキシで静的リソースをキャッシュしてしまいpreforkなオリジンサーバにリクエストがあまり来ないようにすればよいでしょう。
また、これは通信環境が悪くて遅いクライアントの影響を小さくする対する対策にもなります。
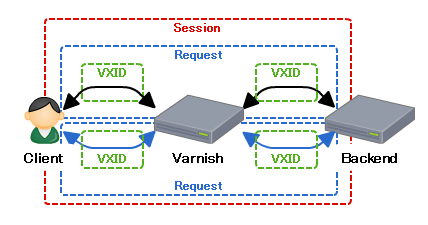
リバースプロキシのMWはNginxやApacheやVarnishを使うと良いと思います。僕はVarnishが好きです。
その動的コンテンツは更新されますか?
サイトにもよると思いますが、リクエストしても毎回同じコンテンツを返す場合はリバースプロキシでキャッシュすることを検討するのもよいでしょう。
高コストなLLでページを生成する必要がなくなるため、突然buzzっても割と耐えられるようになります。
また全体でサーバコストを減らすことも可能でしょう。
何かしら情報を取得するためにLLを動かす必要があるというのであれば、それはjsで代用ができないかとか検討するのもよいでしょう(もしくはESIを検討するのもよいでしょう)
動的コンテンツをキャッシュすることで一気に軽く、そしてコストを減らせるでしょう。
サーバ情報を隠そう
パフォーマンスとは関係ありませんが
単純に危ないので不要な情報(特にバージョン情報)は消すようにしましょう。
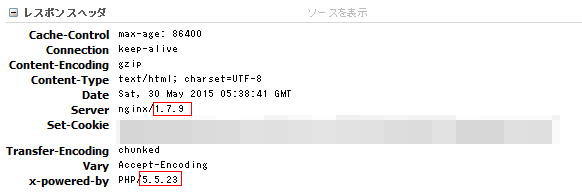
phpのバージョンまで出てる
HTTPS(SSL/TLS)の設定を確認しよう
少し前に話題になったPOODLEやHeartbleedなど(直近だとLogjamやFREAK)HTTPSに関わる脆弱性をよく聞きます。
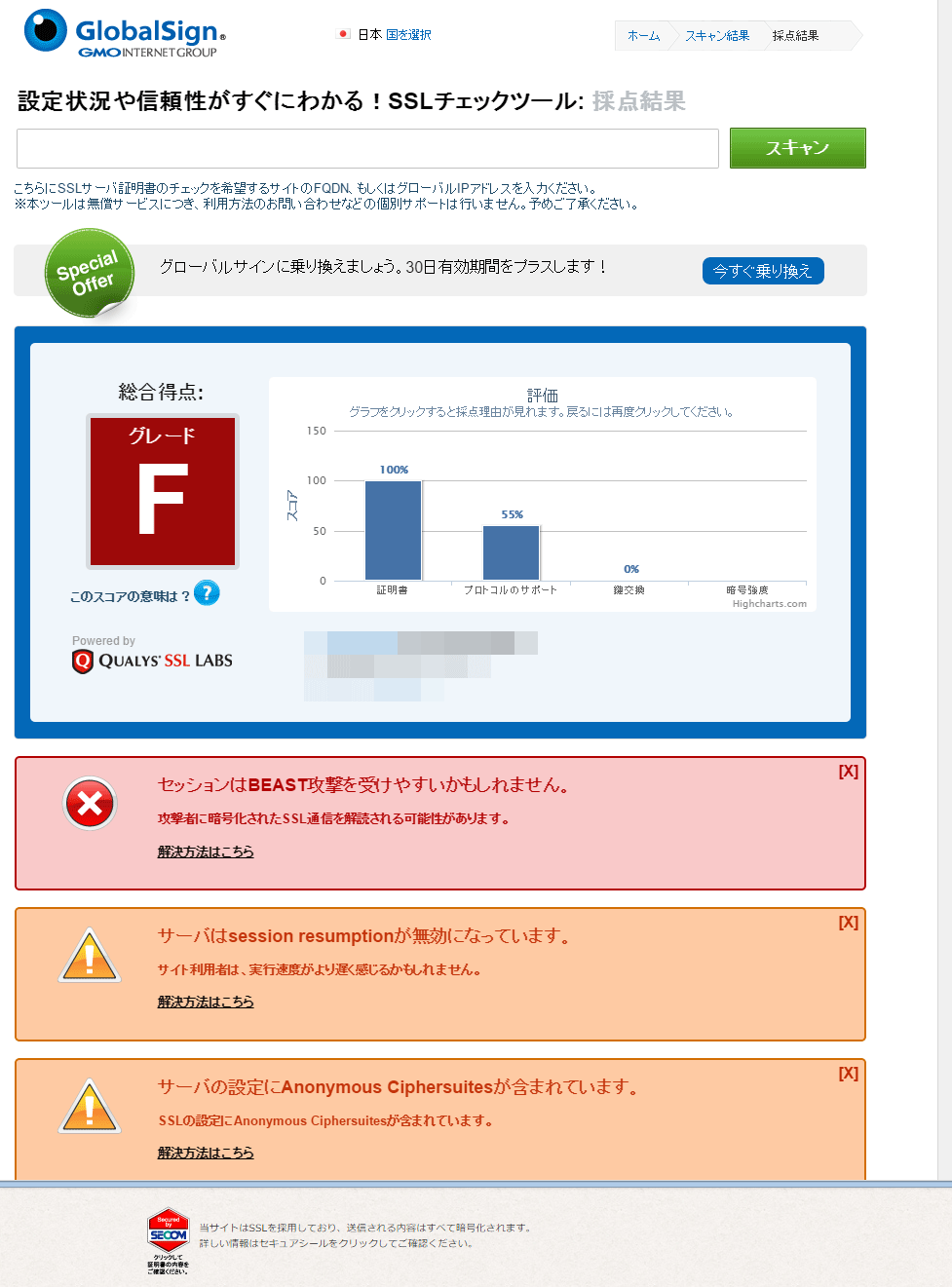
いろいろあるものの今自分のサイトの状態がわからないのであればとりあえずGlobalSignかQUALYS SSL Labsの診断をやってみましょう。
GlobalSignの診断はSSL Labsのを元にしているのですが日本語なので分かりやすいです。
とりあえず指摘事項を見つつサーバ設定を直していくと良いでしょう。(セキュリティだけではなくパフォーマンスに影響する項目もあります)
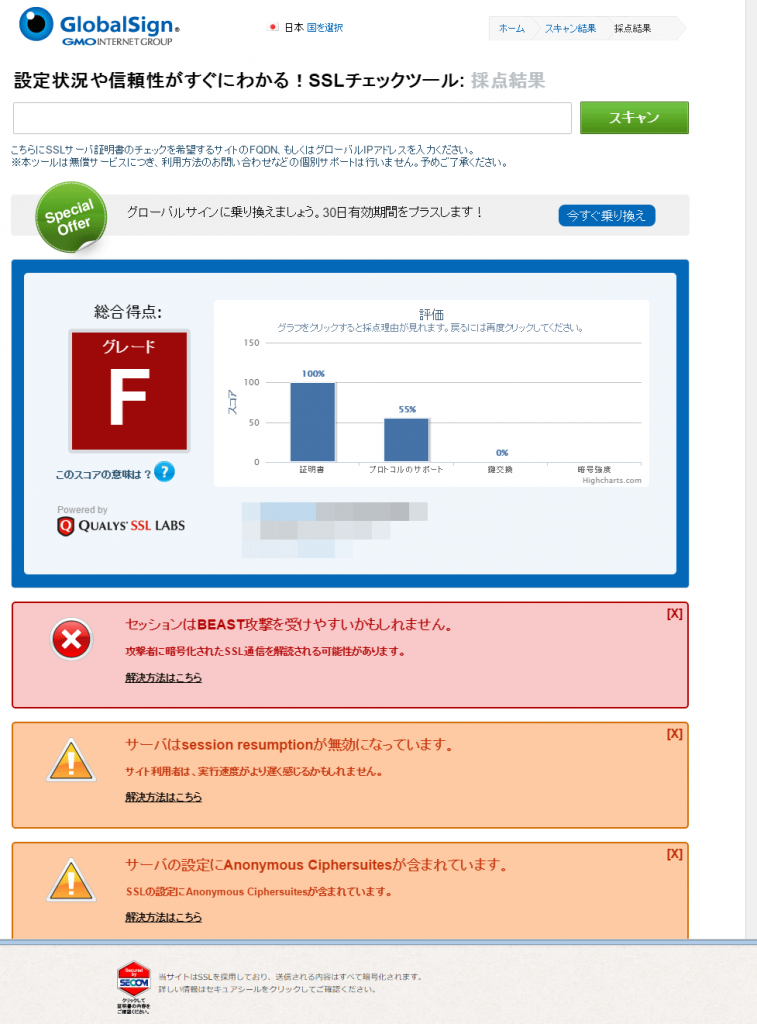
SSL使用をアピールしてるものの設定は・・・
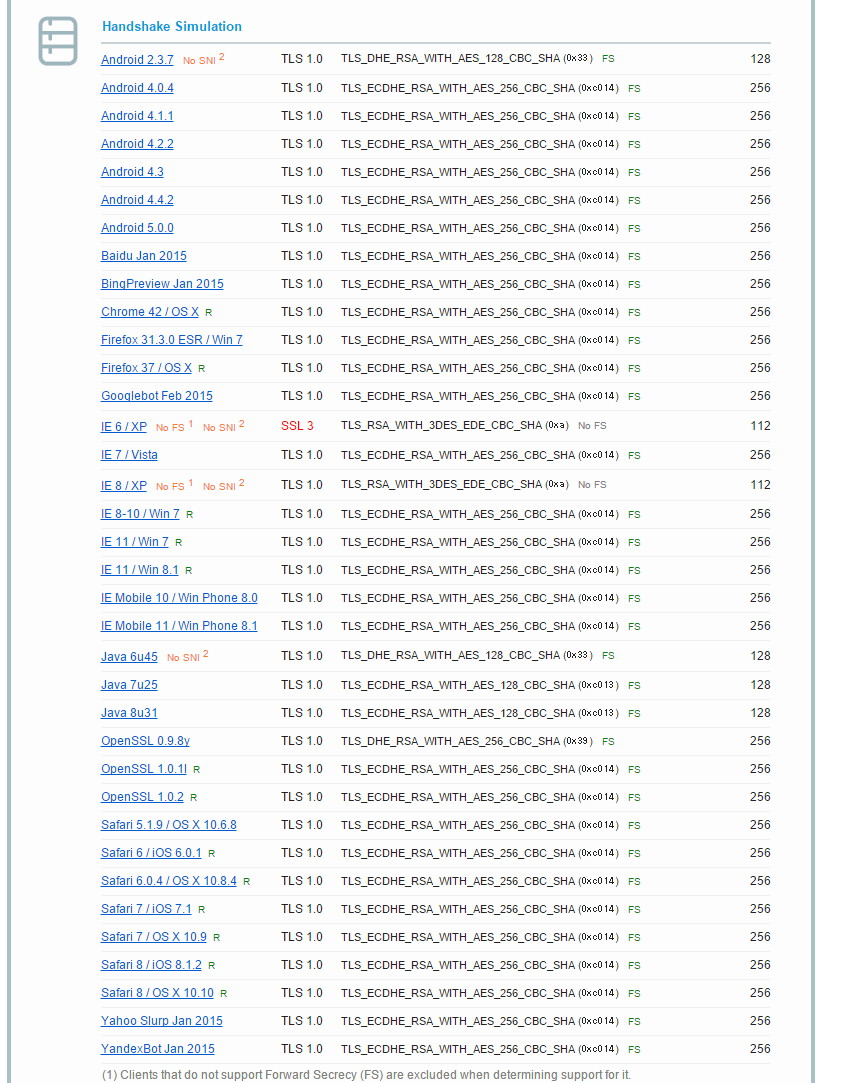
SSL Labsのほうだとどのような環境で見れるかも確認できるので両方みると良いと思います。
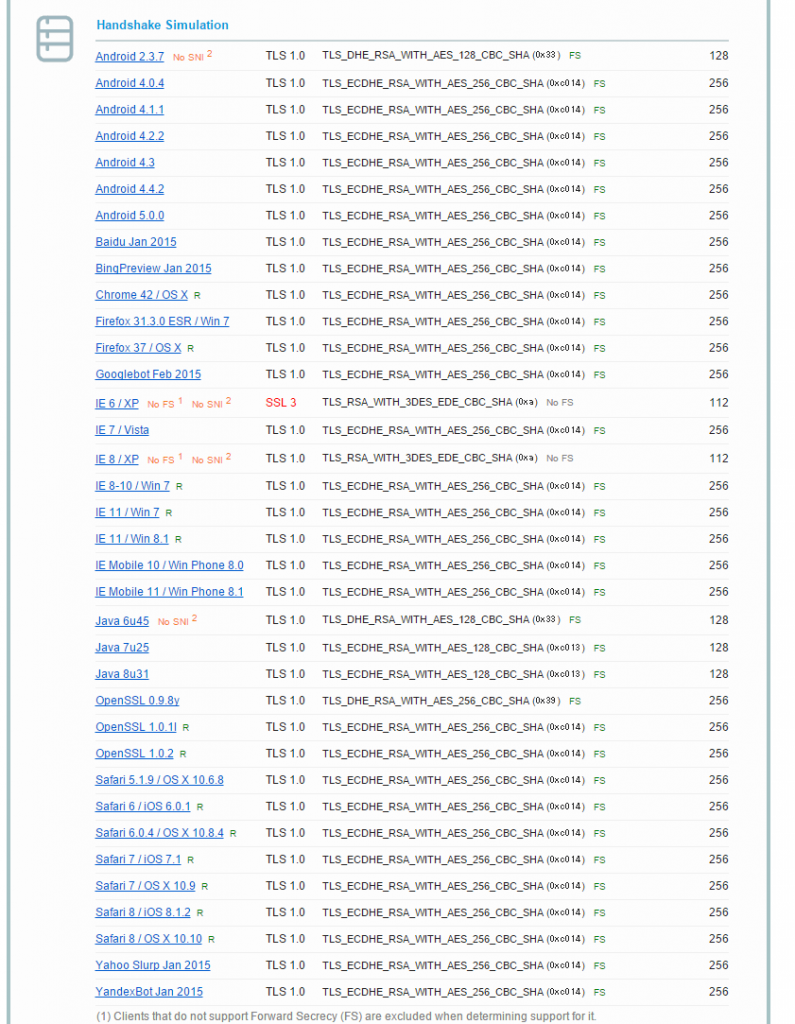
SSL Labsは環境のシミュレーションをやってくれる
古いAndroidやガラケーをサポートする必要がある場合などサポートするべき環境などによって設定は変わるのでAを取るのは難しいのですが可能な限り不用意な設定等は排除したいものです。
そのVaryヘッダ本当に大丈夫ですか?(2017/02/17追記)
CDNやリバプロ等のクライアント・サーバ間でキャッシュを行う場合きちんと考えて設定したいVaryというヘッダがあります。
多くの場合はVary: Accept-Encodingが指定されていることが多いです。
このヘッダが意味するところは
Accept-Encodingによって内容が変わるので、中間でキャッシュする場合はクライアントから送られるAccept-Encodingヘッダ毎にキャッシュ持ってねということです。
cssやjsはgzip圧縮して転送したりしますが、gzipに対応していないクライアントも存在します。
もし、Varyを指定してない状態で、先にgzip圧縮されたcssが中間でキャッシュされ、gzip非対応のクライアントでリクエストをするとgzipなcssがレスポンスされて困ってしまいます。
そのためVaryを使うことでこのURLはAccept-Encodingで内容が変化することを宣言しているわけです。
なるほど、これは便利だということでUser-Agent(以下UA)を指定をするサイトもあるようです。
おそらくPC・スマホ・ガラケーでも同一URLで処理したいということなのかなと思いつつ
これは非常にもったいない設定です。
なぜならUser-Agentは非常に多いため、キャッシュのヒット率が低下します。(もちろんパフォーマンスも)
わかりやすいところだと、AndroidのUAは機種名が入ってたりします。
つまりその機種毎・そしてバージョン毎に個別のキャッシュが作られてしまいます。
もちろん意図したものであれば問題ないのですが、大抵の場合はなんとなく設定されているのでは考えてしまうものが多いです。
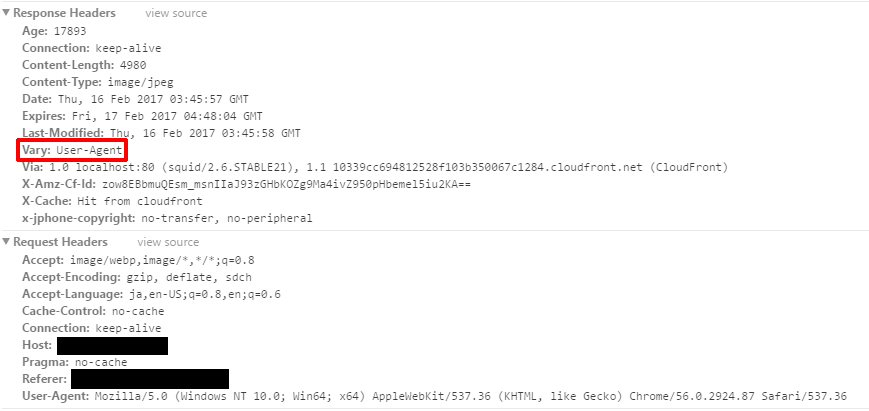
上記は割と大きな音楽・本の配信サイトなんです。見たところ画像をパラメータによって動的にリサイズしておりそれをキャッシュしようとしていますがVaryにUAを指定しています。
当然なのですがUAを変えてリクエストをしたところMissになりました。
パラメータで生成条件を変えているためおそらくUAでユニークである必要はないと考えられ、そもそも外すか(画像は既に圧縮されてるのでgzipがあまり効かないためそのまま送ることが多い)Accept-Encoding指定でよいのではと思います。
ちなみに、CDNやミドルウェアによってはこのあたりを賢く制御(PC/スマホで個別にキャッシュを持つ)などもできたりします。
CDNやキャッシュを使う場合は、Varyに気をつけてみてください。
(小ネタ)クライアントとCDN/リバースプロキシでのキャッシュの違い
さて、クライアントでのキャッシュとCDN/リバースプロキシでのキャッシュは何が違うのでしょうか?
すごく簡単にいうとそのキャッシュが参照されるクライアント数が1なのか多なのかだと考えています。
当然ながらクライアントに格納されているキャッシュは他のクライアントに参照されません。
そのため極端なことを言ってしまえば、サイトがほぼ100%直帰されて再訪もないのであればクライアントのキャッシュをいくら頑張っても無意味です(そんなサイト無いと思いますが)
対するCDN/リバースプロキシでのキャッシュはその場合でもうまく動きます(ちなみに/としていますがCDN=リバースプロキシと言ってるわけではないです併用するのが大事です)
両者の違いを意識してうまく併用できると良いかなと思います
まとめ
もちろんサイトの状況によっていろいろ変わると思いますが
これらの対策をやるだけで割とサイトのパフォーマンスは良くなると思います。
また、今回紹介したのは割と基本的なところで他にもいろんな高速化の方法があります。
他にも最低限気にすべきこともありますがパフォーマンスとはあまり関係ないので削りました。(なんとインターネット上にmysqlのポートを開けてるとこがありました・・)
みなさんのサイトが速くなればいいなーとおもってます。
参考になれば嬉しいです。
参考リンク
パフォーマンスの最適化
ESIの効果と気をつけた点
Varnishを多段にする利点と注意するところ
SSL証明書のインストールチェックはどのサイトを利用すべきか
SSL のパフォーマンスでお嘆きの貴兄に
Webサーバ勉強会#5に参加してきましたよ
")
")


 #nextwebconf")