サービスをスケールさせるためにロードバランサー(以下LB)をよく使用します。
LBは大量のリクエストをノードに振り分けるは当然で、他の重要な機能の一つしてヘルスチェックがあります。
御存知の通りノードが死亡した場合に切り離しを行う機能です。
箱モノのLB(F5やA10など)やソフトウェアで行うHAProxy、Varnishなどでのヘルスチェックの「行う側」の設定方法はよく記事で見かけるのですが
ApacheやNginxなどのヘルスチェックを「受ける側」についての記事は余りないように思えたので
今回HTTPでのヘルスチェックを小ネタとして書こうと思います。
(別にMySQLのヘルスチェックでも考え方はそんなに変わらないです)
全般的に私としての考えなので、人によっては違うかもしれないです。参考程度にどうぞ。
ヘルスチェックの設計
ヘルスチェックを設計する場合に気をつけることはたった一つで
「そのヘルスチェックでどこの範囲の正常性を担保するか」ということです。
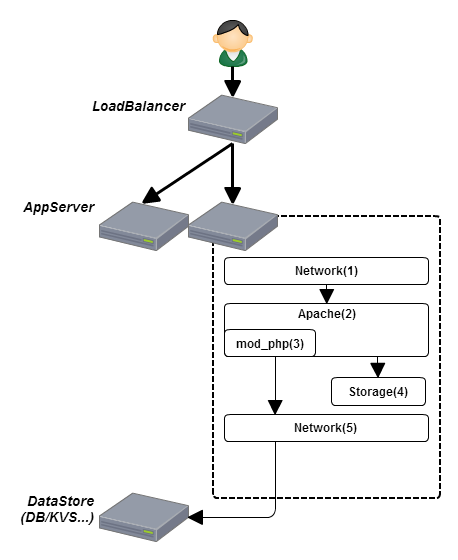
Apache上でPHPが動いているAppノードを例で考えてみましょう(すごくざっくりな図です)
※この記事ではノード=VMインスタンスや物理的なサーバ、サーバ=Apacheなどとして書いています
静的ファイルでのチェック
よくやるのは/healthcheck/check.htmlのような静的なファイルを置いてLBからヘルスチェックを行う方法です。
これでチェックが出来る範囲について考えてみましょう。
- LB<->Appノード間のネットワーク
- Appノードのネットワークの状態(ソケットを使い切ってないか等)
- サーバ(Apache)が起動しているか
- ファイルが存在して取得できるかどうか
ざっくりコレぐらいチェック出来ます。
しかしこれではPHPが動くかどうかのチェックはできません。
動的ファイルでのチェック(1)
単純にPHPの動作をチェックするということで
<?php echo "ok";
というPHPでチェックします。
これにより更に
- PHPが動作するか
のチェックが追加で可能になります。
簡単なチェックではありますが、PHPが動く事をある程度保証できます。
ここである程度と言っているのは使用しているextensionはチェックしていないからです。
私は過去にapc_fetchでのspinしていることを見たことが有りますがこれではチェックできません。
どこまでチェックできるのか、それをヘルスチェックでチェックするのかについて把握出来るようにしましょう。
動的ファイルでのチェック(2)
サービスページのトップページなどをヘルスチェックの対象としてみたケースを考えてみましょう。
ここでチェック出来るのはトップページから呼ばれるDBやKVSも含めたサービスの一部分です。
ヘルスチェックとしては比較的網羅的で素敵に見えます。
しかし、例えばDBが高負荷で一時的に応答が不可能になった場合について考えてみましょう。
その場合すべてのノードがLBのヘルスチェックにFailする可能性があります。
ここで重要なのがAppノードは正常なのにです。
一体何をチェックするのか
先ほどの例でトップページをチェックした場合は他のノード(DB等)の影響でFailすることがあることを説明しました。
これはヘルスチェックとして適切かというとLBから行う「サービス」のヘルスチェックという点ではある程度適切ですが「ノード」のヘルスチェックという点では不適切です。
逆に単純なコードでのチェックや静的ファイルでのチェックは「ノード」のヘルスチェックという点では適切ですが「サービス」のヘルスチェックという点では不適切です。
では「サービス」のチェックを行いたいためにトップページをヘルスチェックするのは正しいことでしょうか?
これはどのような考えでヘルスチェックを行うかによって変わります。
要はLBでなにを行いたいのかということです。
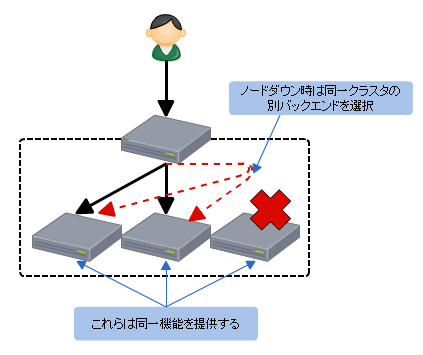
最初に書いたとおり多くの場合は大量のリクエストの負荷分散を行うために複数のノードを纏めてクラスタとしています。
ここで提供/保証したいのはサービスの継続性ではなくクラスタの継続性です。
つまりLBが行うべきなのは負荷分散を行い、異常を示したノードを切り離してクラスタを継続させることです。
複数の仕事を一つでやろうとすると複雑になったり、考慮漏れがあったりするのでそれは監視などにわけてもいいでしょう。
ではLBでサービスの継続性を目的としてはいけないかというとそうではありません。
ただ、非常に難しいのです。
ヘルスチェクの設計で重要な点として述べた「そのヘルスチェックでどこの範囲の正常性を担保するか」ということで考えてみましょう。
ノード単位であればすべてを網羅出来るわけではないものの疎通が出来る、LISTENしているなど比較的少ない要素でほぼ正しく動く状態ということを担保でき比較的わかりやすいです。
しかしサービスは非常に多くの機能から構成されています。ログイン、投稿、課金などなど一体全体どの範囲をチェックするのかという問題が出てきます。
LBですべてのチェックを行う事は事実上不可能です。(極端な事を言えば数秒毎にJenkins叩いて正常性確認できるでしょうか?)
もちろんうまく範囲を定義出来て合意が取れればそれでも構いませんが、サービス全体のことも何らかの形でケアしないといけません(これについてはノード単位でも同じですが程度の問題です)
というかLBで完結する必要はなく監視システムと連携してアラートが上がったらキルスイッチでそのサービスをメンテ・Sorryページに飛ばすということでしょう。
そのキルスイッチを持つのがLBなのかサービス側なのかそれとも両方なのかは設計次第となります。
小ネタ:高負荷でのSorryページについて
高負荷になった時にSorryページを出すのは非常に魅力的です。
しかし高負荷になった場合に一律でSorryを出してもよいものでしょうか?
例えばECサイトで決済をしようとしているユーザ・カートに商品を入れているユーザ・単純にページを見ているユーザを一律で切ってもいいのかという話です。
これはヘルスチェックを「する側」・「受ける側」、そしてサービス側での設計が必要ですが、Sorryに飛ばすのは単純にページを見ているユーザだけにとどめて
決済をしようとしているユーザやカートに商品を入れているユーザは通過させるということも可能です。(識別子をつけておく)
単一ノードに複数のサーバがあって関連する場合

単一のノードに例えばApacheだけではなくlocalのmemcachedをたてるケースが存在します。
この場合はどうするべきでしょうか?
これも結局どの範囲を保証するかを考えるだけですみます。
memcachedが動作していることが必須であればヘルスチェックのコードでmemcachedのstatsを叩くコードも含めればよいでしょう。
逆にコード側でlocalのmemcachedが死んでいた場合でも別に問い合わせをするなどで致命的な問題を引き起こさないとかケア出来てるのであればなくてもよいでしょう。(監視からの障害対応などでの対応)
クラスタ内のノード数が少なく、なるだけノードを切り離したくない+サーバが落ちても別に問い合わせするなどして影響が無いのであればそれでも良いと思います。
ざっくり言うと、複数ノードに跨るヘルスチェックは辞めたほうがよく、単一ノードで複数のサーバがある場合はそれを通しでチェックするのは良いと考えています。
Proxyのヘルスチェック
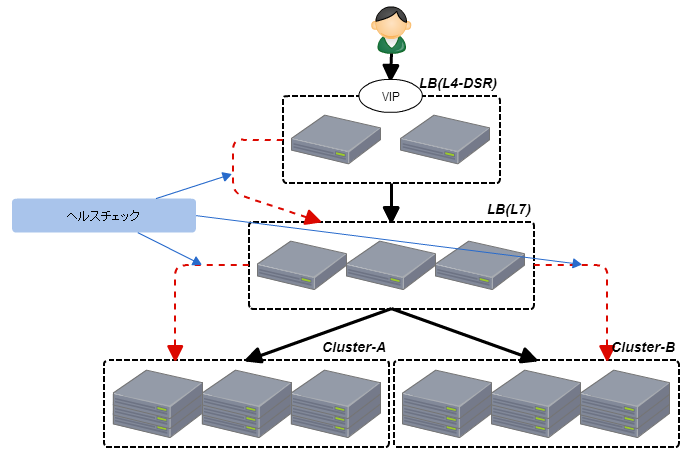
LVSとProxyを組み合わせて上記のような構成を取ることが有ります。(LB-L7がProxyです)
その場合LVS-ProxyとProxy-Appノードの2つです。
Proxy-Appノード間は今まで紹介してきた通りなのですが、LVS-Proxyは注意が必要です。
簡単にいうとProxyはリクエストを中継するためにあるのでヘルスチェックのリクエストもノードのクラスタに飛ばしてしまうことがあることです。
そうしてしまうと複数のノードを跨るヘルスチェックとなってしまうのと、特定のクラスタのヘルスチェックの結果に引きづられてしまいます。
大抵ヘルスチェックはIPアドレス指定で行うので、複数のクラスタ定義がある場合はミドルウェアによりますがだいたい先頭の定義に振り分けられるからです。
そのためRewriteでヘルスチェックのURLであればそのまま200を返すのがよいでしょう。
ここでもう一つ注意なのがRewriteでヘルスチェックの結果を返すようなことをAppノードでは避けたほうがいいということです。
わざわざ書いているのはApacheはProxyにもWebサーバにもなり、ヘルスチェックの設定を流用してしまって思わぬ事故につながることもあるからです。
きちんと範囲を意識して、そのロールに適切なヘルスチェックの設定なのかを考えるべきです。
ヘルスチェックと障害調査
「そのヘルスチェックでどこの範囲の正常性を担保するか」ということをある程度把握しておくと障害調査の時に楽ができます。
何故と言うと障害調査を行う場合にヘルスチェックによってそこまでの切り分けができるからです。
例えばサービスがダウンしていて、そのサービスが乗っているクラスタはヘルスチェックによって正常であるならば少なくともLB-ノード間は異常が無いのであろうとわかります。
逆に把握ができていない場合はそれらも障害切り分けの時に考慮する必要がありますし、ヘルスチェックの設計自体に問題がある場合はそもそもそこが障害ポイントともなり、調査に時間がかかる原因になりかねません。
まとめ
ヘルスチェックを「受ける」側のことについて書いてみました。
単純に静的ファイルを置く、コードを置く、RewriteでOKするなど様々な返し方がありますが
間違った使い方をすると意図せず切り離されたり、あれ?切り離されていない?といった事になります。
そのヘルスチェックで何をチェック出来るのかを考えて設計するのがよいと思います。
またヘルスチェックは万能ではなく他のシステム(特に監視など)と補完の関係にあると考えています。
ヘルスチェックは機械的に判断できる要素を設定して、監視は他の判断や複数の要素(ノードやサービスのコード等)に跨るでもよいかなと思います。
うまく使うことでサービス全体の可用性を向上できるといいなーと思います。
